
EmoPy: A Machine Learning Toolkit For Emotional Expression

Thursday, 6 September 2018
I recently led a project team at Thoughtworks to create and open source a new Facial Expression Recognition (FER) toolkit named EmoPy. The system produces accuracy rates comparable to the highest rates achievable in FER, and is now available for anyone to use for free.

This article explains how the EmoPy system is designed and how it can be used. It will examine the architectures and datasets selected, and illustrate why those choices were made. This should be helpful for those considering using EmoPy in their own projects, contributing to EmoPy, or developing custom toolkits using EmoPy as a template.
Facial Expression Recognition is a rapidly-developing field. If you are new to this technology, you might like to read my previously published overview of the field of FER.
Our aim is to widen public access to this crucial emerging technology, one for which the development usually takes place behind commercially closed doors. We welcome raised issues and contributions from the open source development community, and hope you find EmoPy useful for your projects.
The Origins of EmoPy
The EmoPy toolkit was created as part of Thoughtworks Arts, a program which incubates artists investigating intersections of technology and society. Our development team supported the artist-in-residence Karen Palmer to create a new version her interactive film experience, RIOT.
RIOT positions viewers first-person in an installation space watching a video unfold in front of them. A dangerous riot is in progress, and viewers meet filmed characters, including looters and riot police. Each viewer’s facial expressions are recorded and analyzed via a webcam, which feeds into EmoPy as the movie unfolds.

The story branches in different directions depending on each viewer’s perceived emotional response to the film. Each viewer encounters different pathways through the story, depending on whether their dominant perceived emotion at given moments is fear, anger, or calm.
As we developed new features for RIOT, we generated new requirements for EmoPy, which was created in tandem as a standalone emotion recognition toolkit. The system was built from scratch, inspired initially by the research of Dr Hongying Meng, one of Karen’s previous technical partners. Dr Meng’s time-delay neural network approach has been approximated in the TimeDelayConvNN architecture included in EmoPy.
#1. Neural Network Architecture
The first consideration when evaluating EmoPy is the choice of initial model architectures. Neural network architectures are combinations of layers which feed outputs to each other in sequence. We chose these initial architectures based on approaches we encountered during our general research of existing FER implementations.
Very different performance results are achieved depending on the choice and sequence of layers making up neural network architectures. To improve on what we found in our research, we began a process of experimentation and testing with various combinations.
The example shown below is ConvolutionalNN, which under test proved to be the best performing of the convolutional architectures. This architecture has layers arranged as shown in the diagram below.
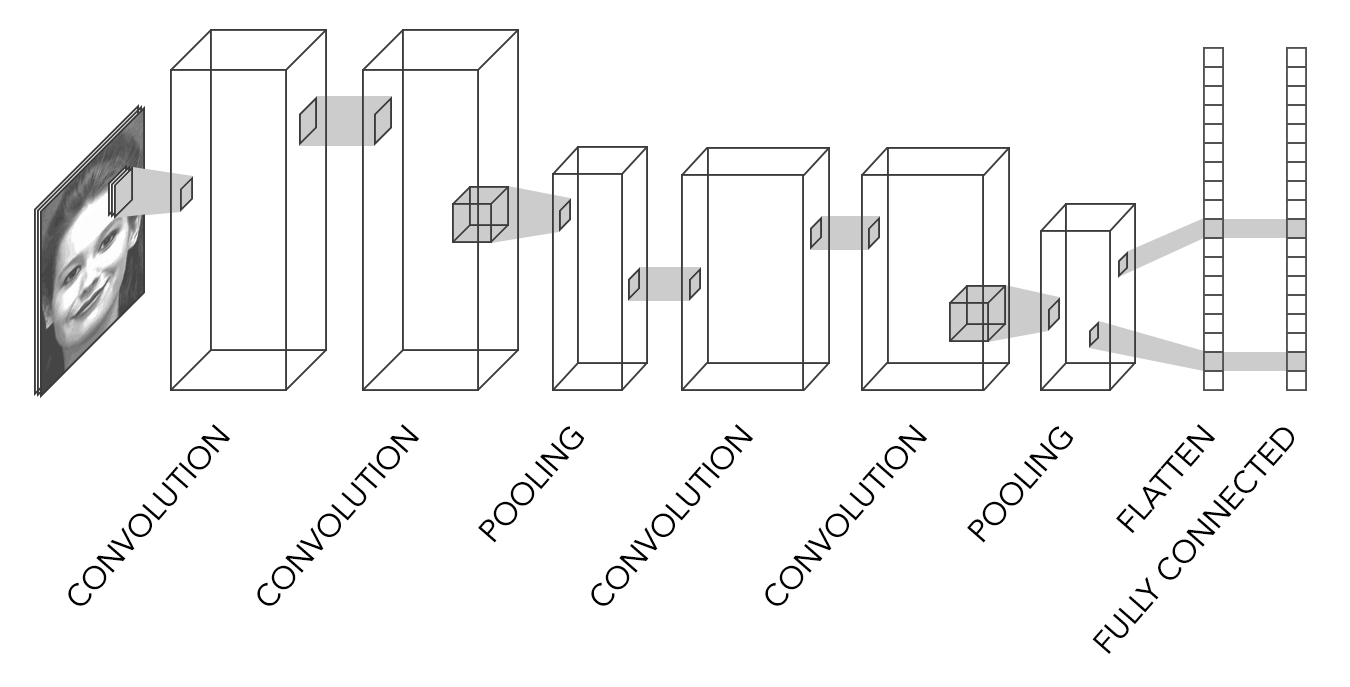
The image shows the differences in size of each of the network layers. Pooling layers are used to reduce the input space and thus complexity and processing time. The flattening layer converts the output of the previous layer to a one dimensional vector and the final layer takes that vector and calculates a final classification output.
Some architectures have many more layers than shown in the example diagram above. The TransferLearningNN model for example, which has Google’s Inception-v3 architecture, has hundreds of layers.
The full list of initial architectures provided with EmoPy are listed in the neuralnets.py class definition file, as well as in the EmoPy documentation. A comparison of neural network models is also included in the EmoPy readme and also in this overview article.
Each of the four subclasses in neuralnets.py implements a different neural network architecture using the Keras framework with a Tensorflow backend, allowing users to experiment and see which one performs best for their needs.
#2. Selecting Datasets
The next consideration in relation to EmoPy is the selection of datasets. As described in the overview article, ideally our neural networks would be trained with millions of image samples. This would increase accuracy and improve generalizability of the models.
Unfortunately datasets of this size don’t exist publicly, but we do have access to two public datasets — Microsoft’s FER2013 and the Extended Cohn-Kanade dataset.
The FER2013 dataset contains over 35,000 facial expression images for seven emotion classes, including anger, disgust, fear, happiness, sadness, surprise, and calm. The image label breakdown shows a skew towards happiness and away from disgust, as demonstrated in the table below.
| Emotion | Quantity |
|---|---|
| Disgust | 547 |
| Anger | 4953 |
| Surprise | 4002 |
| Sadness | 6077 |
| Calm | 6198 |
| Happiness | 8989 |
| Fear | 5121 |
The Cohn-Kanade dataset is made up of facial expression sequences rather than still images. Each sequence starts with a neutral expression and transitions to a peak emotion.

The peak emotions available are calm, anger, contempt, disgust, fear, happy, sadness, and surprise. The Cohn-Kanade dataset contains 327 sequences, from which we extracted still images.
Since the FER dataset is much larger, we trained our models with 85% of its images and validated with the remaining 15% as well as with the Cohn-Kanade dataset during testing.
We used data augmentation techniques to improve our model’s performance, applied to both datasets. These techniques create an increase in the size of existing datasets by applying various transformations to existing images to create new ones. Example transformations we used are mirroring, cropping, and rotation.

Application of data augmentation drastically increased the accuracy of our neural networks. This was particularly true for the ConvolutionalNN model, whose accuracy increased by about thirty percent.
#3. The Training Process
The third important consideration relating to EmoPy is the process of training the neural networks with the selected datasets. First, we split the dataset into two parts: the training set and validation set. Next we took sample images from the training set and used them to train our neural networks.
The following process occurs for each image passed through a neural network during training:
- The neural network makes an emotion prediction based on its current weights and parameters
- The neural network compares the predicted emotion to the true emotion of the image to calculate a loss value
- The loss value is used to adjust the weights of the neural network
The purpose of the training set is to build the model by adjusting its weights to more accurately make predictions in the future, with each iteration of the process refining what the network has ‘learned’.
The validation set is used to test the neural network after it has been trained. By having a separate set of sample images in the validation set which were not used for training, we can evaluate the model more objectively.
The training accuracy describes how well the neural network is predicting emotions from samples in the training set. The validation accuracy shows how well the neural network is predicting emotions from samples in the validation set. Training accuracy is usually higher than validation accuracy. This is because the neural network learns patterns from the training samples which may not be present in the validation set.
A common problem with machine learning models is to suffer from overfitting. This is when the neural network learns patterns from the training samples so well that it is unable to generalize when given new samples. This is seen when the training accuracy is much higher than the validation accuracy.
#4. Measuring Performance
The fourth and final consideration of EmoPy is the measurement of performance. How accurate are given architectures when predicting emotions based on the training set, and the validation set?
In our tests, the ConvolutionalNN model performed the best, especially after adding data augmentation to our image preprocessing. In fact, for certain emotion sets such as “disgust, happiness, surprise” this neural network correctly predicts nine out of ten images it has never seen before.
| TransferLearningNN | ConvolutionalNN | ConvolutionalLstmNN | ||||
|---|---|---|---|---|---|---|
| Emotion Set | Training Accuracy | Validation Accuracy | Training Accuracy | Validation Accuracy | Training Accuracy | Validation Accuracy |
| Anger, fear, surprise, calm | 0.6636 | 0.4947 | 0.6064 | 0.5637 | 0.6451 | 0.5125 |
| Disgust, happiness, surprise | 0.7797 | 0.7877 | 0.9246 | 0.9045 | 0.7391 | 0.7074 |
| Anger, happiness, calm | 0.5385 | 0.5148 | 0.7575 | 0.7218 | 0.7056 | 0.6653 |
| Anger, fear, surprise | 0.771 | 0.5914 | 0.6851 | 0.6503 | 0.5501 | 0.3523 |
| Anger, disgust | 0.9182 | 0.9094 | 0.958 | 0.9404 | 0.8971 | 0.9118 |
| Anger, fear | 0.6691 | 0.6381 | 0.7791 | 0.7029 | 0.5609 | 0.5567 |
| Disgust, surprise | 0.9256 | 0.9019 | 0.9893 | 0.9624 | 0.8846 | 0.8806 |
The ConvolutionalLstmNN model performed decently on still images, but is actually an architecture meant to be trained on time series samples. The TransferLearningNN model performed very well on some subsets of emotions, but the most performant was the ConvolutionalNN model.
Based on these test results, we chose to proceed with the ConvolutionalNN model exclusively when moving forward with the RIOT project.
Analyzing Misclassifications
A useful approach to analyzing and improving neural networks is using confusion matrices. These visual tools illustrate clearly the rates of misclassification alongside correct classifications, providing valuable insights to help adjust the training of future models.
On the x axis of confusion matrices are the predicted labels classified by the neural network, and on the y axis are the actual labels. With a highly accurate model we would expect to see a strong diagonal line, leading from the top-left down to the bottom-right of the matrix. This would show that each of the predicted labels was matching the true labels at a high rate. A less accurate model will produce a more checkered matrix.
The confusion matrices below show the results generated when testing neural networks against both of the datasets used in EmoPy. All of the matrices show results from models which were trained on FER2013. However, importantly, the matrices on the left show results when that network was validated using FER2013. The matrices on the right show results when matrices were validated using Cohn-Kanade.
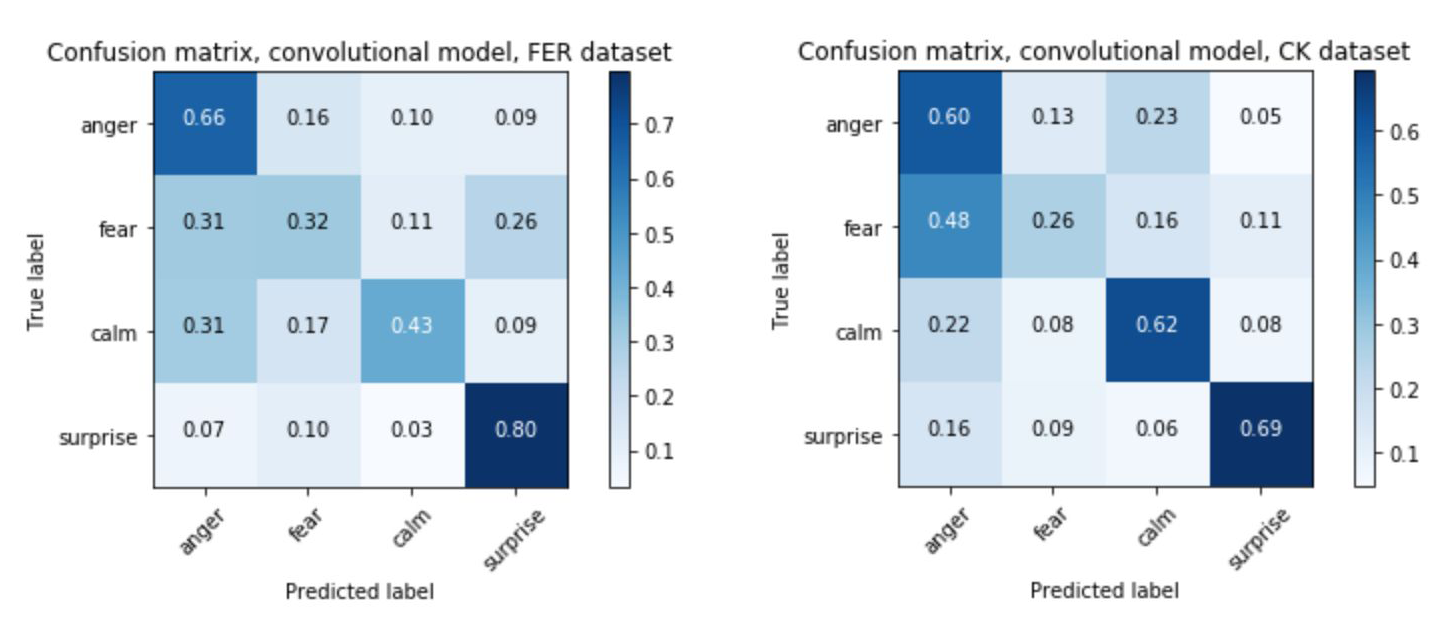
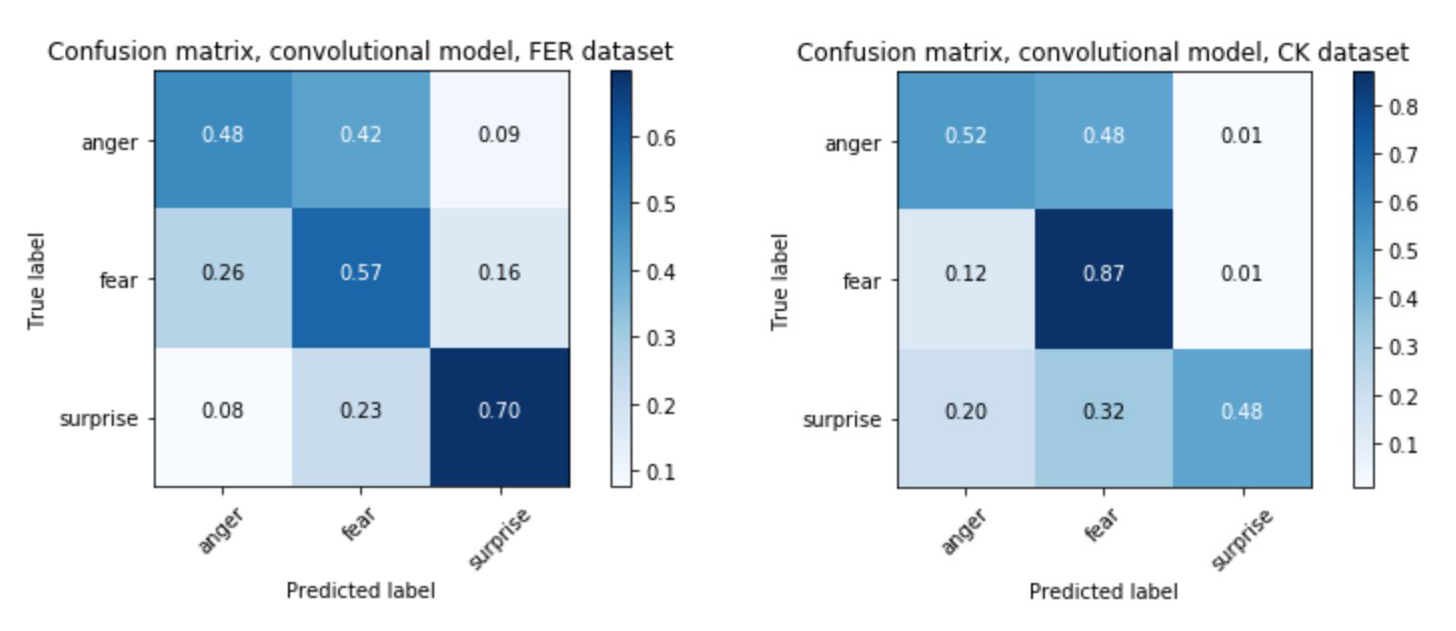
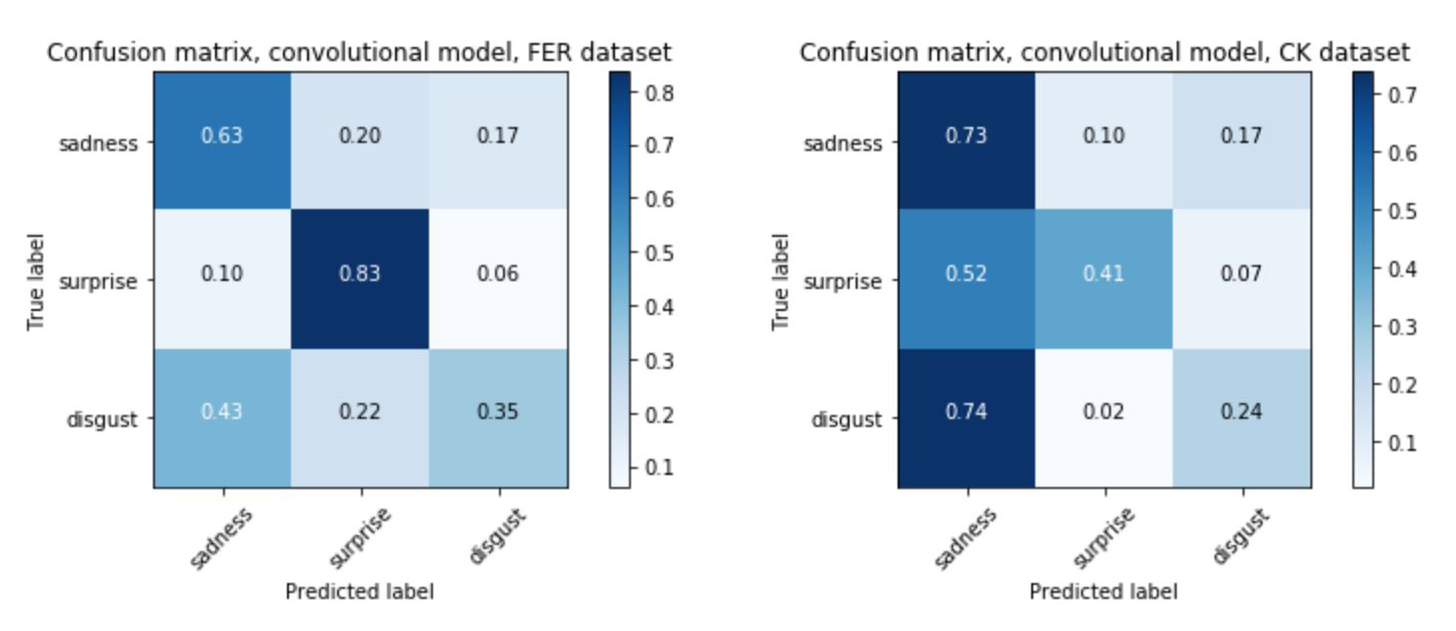
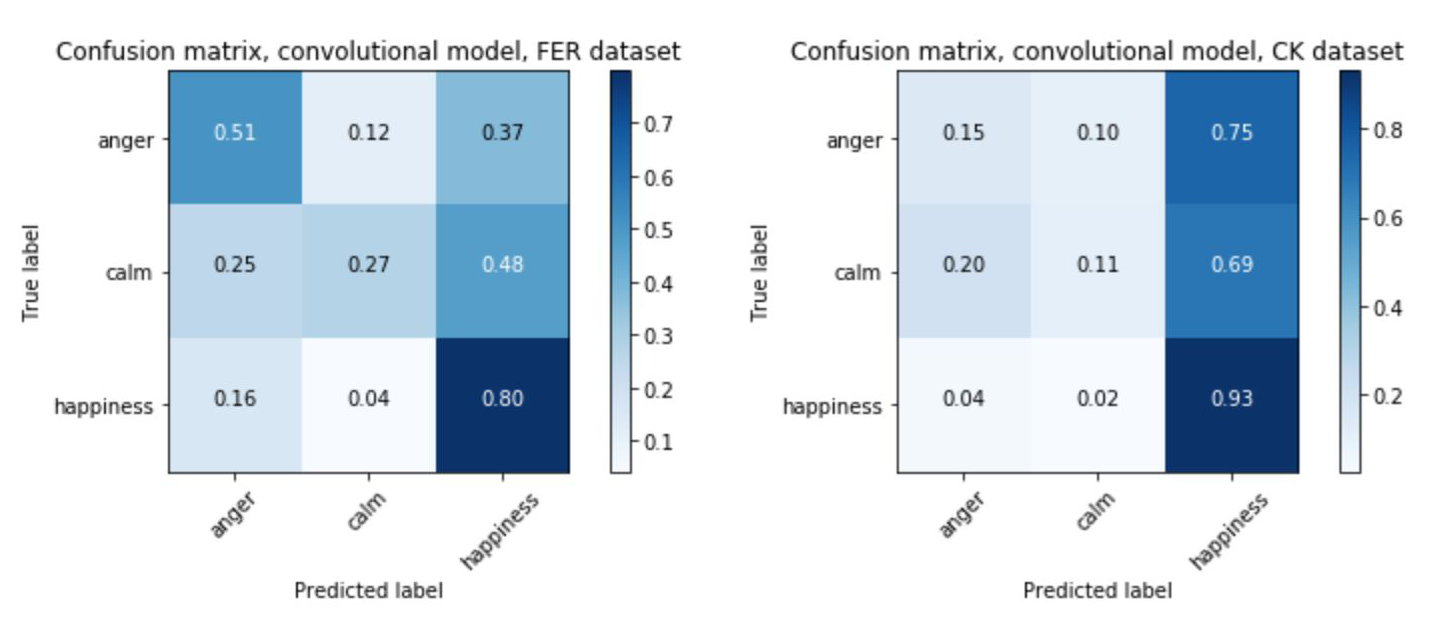
The matrices show that when the validation set is drawn from the same dataset as the training set, validation results tend to be better. This is clear because the ‘accurate’ diagonal is somewhat darker in the matrices on the left. With the matrices on the right, it is harder to trace a dark diagonal. This tells us that the model we are validating doesn’t generalize well.
Below are two image samples, one from each dataset. Notably, images from Cohn-Kanade are all frontal views, whereas images in FER2013 were taken from many different angles.

Moreover, when the Cohn-Kanade dataset was created, participants were given examples of facial expressions and then asked to act them out. FER2013 images are much more varied. They come from many sources on the web — some appear to be raw ‘authentic’ emotions, whereas others are clearly exaggerated or acted out.
Because of these types of differences in datasets, it is important to cross-validate performance using multiple datasets. It’s also important to note how the neural network performs on specific emotions. For example, fear tends to be misclassified more often than other emotions, as seen in the first pair of confusion matrices above. Looking at sample images from each dataset shows why this could be the case.


Facial expressions are by their nature ambiguous, and certain distinct emotions can lead to very similar facial expressions. In the case of fear, sometimes a person’s eyes are open very widely, which can be very similar to anger. Fear can also produce tight lips, which in other moments may be an indicator of calm.
The best way to avoid these misclassifications, particularly in deep learning approaches, is to use the largest dataset possible. Moreover, as shown in the confusion matrices, better results are achieved when training on a smaller quantity of emotion classifications.
Contributing to EmoPy
We have made EmoPy an open source project to increase public access to technology that is often out of reach. The goal of the project is to make it easy for anyone to experiment with neural networks for FER and to share high-performing pre-trained models with all.
Open source projects rely on contributions, and if you find this system useful I hope you’ll consider helping develop it. You can fork the repository and send a pull request, however it might be beneficial to contact one of the EmoPy contributors to discuss your input.
Whether you are considering contributing, utilizing or replicating EmoPy, we hope you find the system useful. We have used an unrestrictive license to enable the widest possible access. However please take a moment to review our guiding principles, which include championing integrity, transparency, and awareness around FER.
We hope to see this technology used for good purposes, and look forward to hearing about your implementations going forward.
Keep on top of Thoughtworks Arts updates and articles: