
Recognizing Human Facial Expressions With Machine Learning

Thursday, 23 August 2018
Machine learning systems can be trained to recognize emotional expressions from images of human faces, with a high degree of accuracy in many cases.

However, implementation can be a complex and difficult task. The technology is at a relatively early stage. High quality datasets can be hard to find. And there are various pitfalls to avoid when designing new systems.
This article provides an introduction to the field known as Facial Expression Recognition (FER). After explaining general features and issues making up this field, this article will look at common FER datasets, architectures and algorithms. Further, it will examine the performance and accuracy of FER systems, showing how these outcomes are driving new trajectories for those exploring automated emotion recognition via machine learning.
Where our experience came from
The information presented in this article is based on a mixture of project experience and academic research. At Thoughtworks we created an FER toolkit named EmoPy, supporting the artist and filmmaker Karen Palmer during her residency with Thoughtworks Arts.
As the lead developer on that project, I worked with a team to help Karen to create a new version of her emotionally responsive film experience, RIOT. We built EmoPy from the ground up to handle the emotion recognition requirements of the RIOT system.

EmoPy is published as an open source project, helping to increase public access to a technology which is often locked behind closed doors. In this follow-up article I explain more about the creation of the EmoPy toolkit, and explain why and how you might use it in your own projects.
Before joining Thoughtworks, I graduated from Stanford with a degree focusing on Artificial Intelligence. A large part of my research was in comparative approaches to machine learning problems, including looking at FER systems.
The overview presented in this article is drawn from both of these experiences, with Stanford and with Thoughtworks Arts.
Classifying images as emotions
Facial Expression Recognition is an Image Classification problem located within the wider field of Computer Vision. Image Classification problems are ones in which images must be algorithmically assigned a label from a discrete set of categories. In FER systems specifically, the images are of human faces and the categories are a set of emotions.
Machine learning approaches to FER all require a set of training image examples, each labeled with a single emotion category. A standard set of seven emotion classifications are often used:
- Anger
- Disgust
- Fear
- Happiness
- Sadness
- Surprise
- Neutral
These emotion classifications are illustrated in the image below, showing representative sample images taken from this 2014 paper on expression recognition.
Classifying an image based on it’s depiction can be a complicated task for machines. It is straightforward for humans to look at an image of a bicycle and know that it is a bicycle, or to look at a person’s face and know that they are smiling and happy.

When computers look at an image, what they ‘see’ is simply a matrix of pixel values. In order to classify an image, the computer has to discover and classify numerical patterns within the image matrix.
These patterns can be variable, and hard to pin down for multiple reasons. Several human emotions can be distinguished only by subtle differences in facial patterns, with emotions like anger and disgust often expressed in very similar ways. Each person’s expressions of emotions can be highly idiosyncratic, with particular quirks and facial cues. There can be a wide variety of divergent orientations and positions of people’s heads in the photographs to be classified.
For these types of reasons, FER is more difficult than most other Image Classification tasks. However, well-designed systems can achieve accurate results when constraints are taken into account during development.
For example, higher accuracy can be achieved when classifying a smaller subset of highly distinguishable expressions, such as anger, happiness and fear. Lower accuracy is achieved when classifying larger subsets, or small subsets with less distinguishable expressions, such as anger and disgust.
Common expression analysis components
Like most image classification systems, FER systems typically use image preprocessing and feature extraction followed by training on selected training architectures. The end result of training is the generation of a model capable of assigning emotion categories to newly provided image examples.
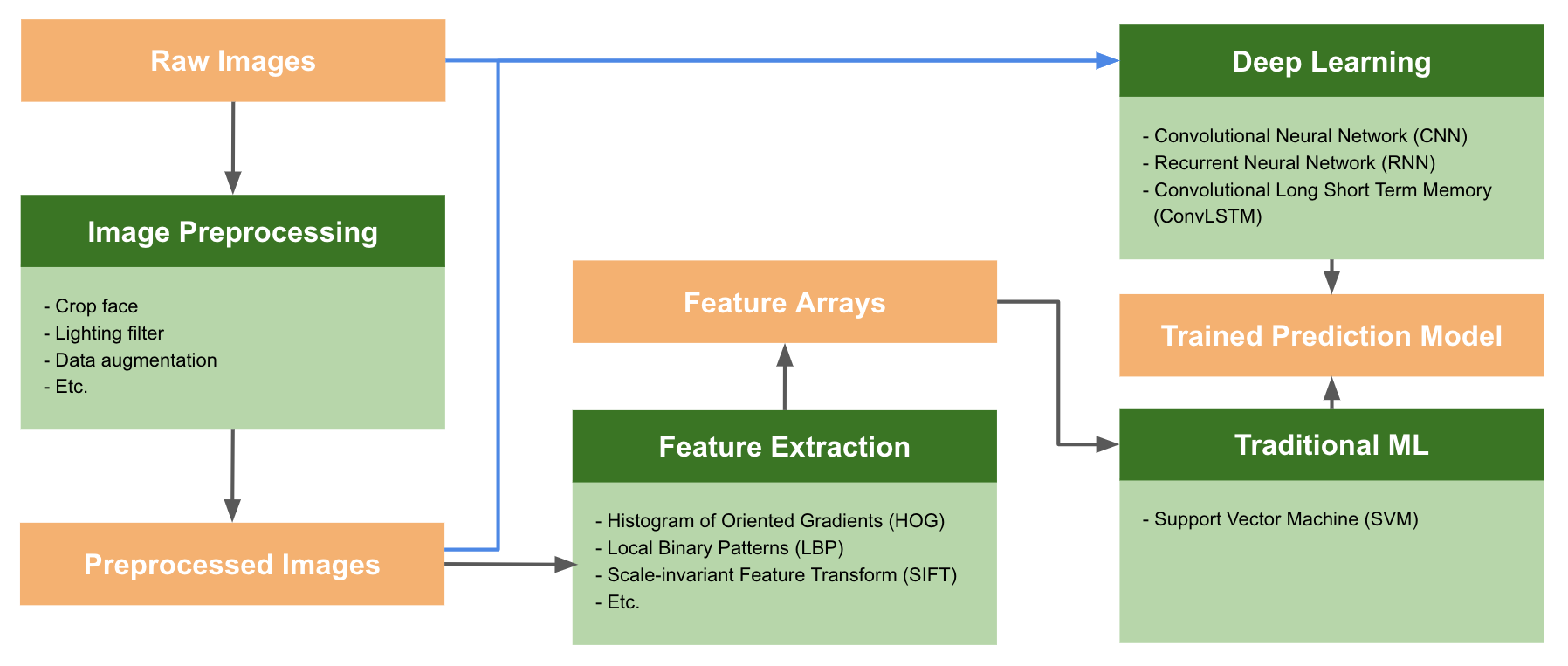
The image preprocessing stage can include image transformations such as scaling, cropping, or filtering images. It is often used to accentuate relevant image information, like cropping an image to remove a background. It can also be used to augment a dataset, for example to generate multiple versions from an original image with varying cropping or transformations applied.
The feature extraction stage goes further in finding the more descriptive parts of an image. Often this means finding information which can be most indicative of a particular class, such as the edges, textures, or colors.
The training stage takes place according to the defined training architecture, which determines the combinations of layers which feed into each other in the neural network. Architectures must be designed for training with the composition of the feature extraction and image preprocessing stages in mind. This is necessary because some architectural components work better with others when applied separately or together.
For example, certain types of feature extraction are not useful in conjunction with deep learning algorithms. They both find relevant features in images, such as edges, and therefore it is redundant to use the two together. Applying feature extraction prior to a deep learning algorithm is not only unnecessary, but can even negatively impact the performance of the architecture.
A comparison of training algorithms
Once any feature extraction or image preprocessing stages are complete, the training algorithm produces a trained prediction model. A number of options exist for training FER models, each of which has strengths and weaknesses making them more or less suitable for particular situations.
In this article we will compare some of the most common algorithms used in FER:
- Multiclass Support Vector Machines (SVM)
- Convolutional Neural Networks (CNN)
- Recurrent Neural Networks (RNN)
- Convolutional Long Short Term Memory (ConvLSTM)
Multiclass Support Vector Machines (SVM) are supervised learning algorithms that analyze and classify data, and they perform well when classifying human facial expressions. However, they only do so when the images are created in a controlled lab setting with consistent head poses and illumination.
SVMs perform less well when classifying images captured “in the wild,” or in spontaneous, uncontrolled settings. Therefore, the latest training architectures being explored are all deep neural networks which perform better under those circumstances. Convolutional Neural Networks (CNN) are currently considered the go-to neural networks for image classification, because they pick up on patterns in small parts of an image, such as the curve of an eyebrow.
CNNs apply kernels, which are matrices smaller than the image, to chunks of the input image. By applying kernels to inputs, new activation matrices, sometimes referred to as feature maps, are generated and passed as inputs to the next layer of the network. In this way, CNNs process more granular elements within an image, making them better at distinguishing between two similar emotion classifications.
Alternatively, Recurrent Neural Networks (RNN) use dynamic temporal behavior when classifying an image. This means that when an RNN processes an input example, it doesn’t just look at the data from that example — it also looks at the data from previous inputs, which are used to provide further context. In FER, the context could be previous image frames of a video clip.
The idea of this approach is to capture the transitions between facial patterns over time, allowing these changes to become additional data points supporting classification. For example, it is possible to capture the changes in the edges of the lips as an expression goes from neutral to happy by smiling, rather than just the edges of a smile from an individual image frame.
Combinations for greater effect
A CNN’s strength in extracting local data can be combined with an RNN’s ability to use temporal context using Convolutional Long Short Term Memory (ConvLSTM). These systems use convolutional layers to extract features and LSTM layers to capture changes in image sequences.
Since deep neural networks are good at identifying patterns in images, they can also be used for feature extraction. Some FER approaches use CNNs to produce feature vectors that are then sent to an SVM for classification. This approach can lead to more accurate results, but is a more complex architecture that requires extra programming effort and an increase in the processing time for each classified image.
The performance of any of these approaches varies depending on the input data, training parameters, emotion set and the system requirements. For these reasons it is important to experiment with various training architectures and datasets, assessing the accuracy and usefulness of each combination.
Finding the right data
As described above, FER models must be trained on a set of labeled images before they can be used to classify new input images. Training for these applications requires large datasets of facial imagery with each displaying a discrete emotion — the more labeled images, the better.
Making a decision on which dataset to train the network on is no easy task, particularly because high quality FER datasets are hard to find. Few such datasets are publicly available, and those that are come with idiosyncrasies which must be understood and taken into account.

The most crucial points to consider when making a dataset selection are the size and quality of the set. The size is arguably the most important, and also the simplest to explain. Ideally a dataset should contain thousands, or preferably millions of images.
Many publicly-available FER datasets come with only hundreds, or sometimes thousands of images. By contrast, Affectiva’s emotion database of over 5 million faces are used for commercial emotion classification products. However, this data is not publicly available.
The quality of a dataset can be considered in various ways. One key consideration is the level of representation of given emotion classifications. It is common for certain emotions to be disproportionately under or over-represented by comparison to others in many datasets. Datasets generally contain far fewer examples of disgust, for example, than happiness or anger.
Another quality consideration is how the emotions expressed in datasets were stimulated. Were actors told to ‘play out’ emotions? Or, were people subjected to authentic emotional experiences, which were then recorded? These two approaches can lead to very different results.
A further consideration is that of head pose. What is the range of head poses, and orientations within the dataset? Crucially: how does that range relate to the range of head poses expected in your production environment?
What is the range of variability in terms of the illumination of the subject in each image, and how does that relate to your target environment? How were images labeled when the dataset was created and by whom? Is there any underlying bias in the labels that will increase the bias of your model?
All of these are questions of dataset quality which should be taken into account when selecting a dataset.
Datasets and target emotions
The selection of a dataset must be conducted with an eye to the set of target emotions for classification. As mentioned previously, some emotional expressions resemble each other. Also, subtle expressions, such as contempt, can be extremely hard to pick up on. Therefore, some datasets will outperform others for certain emotional sets.
Neural networks trained on a limited set of emotions generally tend to result in higher rates of accurate classifications. To give the most extreme example, training on a dataset containing only examples of happiness and anger tends to produce very high accuracy. Two such distinct target classifications mean that the overlap in facial expressive range is minimized.
When neural networks are trained on datasets containing under-represented emotions, such as disgust, they tend to misclassify those emotions. This occurs because multiple emotions can share similar facial features and the dataset does not contain large enough example sets of one emotion to find definitive distinctive patterns.
Transfer learning and data augmentation
All of these issues complicate the dataset selection process, and lead to the need for artificial improvement on whatever dataset you decide to use. This leads some to explore a technique called transfer learning, an approach which takes knowledge gained while solving one problem and applies that knowledge to a different but related problem.
The idea behind transfer learning is to not start training from scratch. Instead, build on top of neural network models which have previously been trained on a large amount of similar data to solve some other similar problem. These models will already come with a set of pre-trained classification weights, which can be used as a starting point, and can be re-trained with a new dataset that uses a new set of classifications.
In the case of FER, neural nets can be used which were pre-trained on a large amount of images to solve general image classification problems, such as Google’s Inception-V3 model. This model is trained on the ImageNet dataset, containing around 80,000 images of 1,000 classes, such as “zebra”, “dalmation,” and “dishwasher,” using a CNN.
However, there is a lot of room for improvement in transfer learning models for FER, as it is very difficult for such models to generalize across datasets. A model trained on one dataset can perform poorly when used to classify images from a second dataset.
Another approach is to use data augmentation to artificially extend the size of datasets. This approach creates copies of original images with altered illumination, applied rotations and mirroring, and other transformations. This approach can improve accuracy of neural networks by increasing the range of states in which source features are encountered during training.
Performance in practice
The tables below show the accuracy results for several recent deep neural net model architectures trained on two different publicly-available datasets:
- Extended Cohn-Kanade, released 2010, and
- Oulu-CASIA, released 2009
The tables come from a 2017 academic research paper that compares its own results, shown in the row labeled ‘Ours-Final’, to other architectures cited in the paper.
| Method | Accuracy |
|---|---|
| AURF [105] | 92.22 % |
| AUDN [106] | 93.7 % |
| STM-Explet [107] | 94.2 % |
| LOmo [108] | 95.1 % |
| IDT+FV [109] | 95.8 % |
| Deep Belief Network [78] | 96.7 % |
| Zero-Bias-CNN [110] | 98.4 % |
| Ours-Final | 98.7 % |
The accuracy results reported in the first table are very high. However it is important to note that these models were trained and tested on the Cohn-Kanade dataset, which contains less than 500 image samples of facial expressions, and that these expressions were ‘acted out’ rather than authentically expressed.
Acted facial expressions are usually more exaggerated than what we see in the real world. If we were to classify new images with these models, they would most likely underperform. Systems trained on datasets created in a controlled lab setting generally fail to generalize across datasets.
| Method | Accuracy |
|---|---|
| DTAGN [111] | 81.46 % |
| LOmo [108] | 82.1 % |
| PPDN [112] | 84.59 % |
| FN2EN [98] | 87.71 % |
| Ours-Final | 89.60 % |
The Oulu-CASIA dataset is composed of six expressions: surprise, happiness, sadness, anger, fear and disgust. The images recorded are taken from a set of 80 people, the majority of which were male. Fifty of the subjects were Finnish, and thirty Chinese.
The expressions were not only acted out, but subjects were given facial expression images to use as examples to imitate. This is another example of a dataset with an extremely controlled creation process that results in lack of training diversity and a model that is unable to generalize.
Developing New Projects in FER
These examples help to illustrate the primary issue faced when developing an FER system — generalizability. How can high accuracy be achieved across multiple datasets containing images with several variations of pose, illumination, and other distinguishing features?
These questions led us to develop our own general FER toolkit, drawing on the best available public data and utilizing the techniques above to produce accurate results. EmoPy is an open source system which is ready for general use.
When implementing new systems, it is necessary to look for weak spots and analyze the characteristics of your particular use-case. This can lead to unexpected solutions, such as when we recorded our own dataset closely matching the target production environment for the purposes of testing trained models.
We determined that the best way to achieve high accuracy in our project was to train our model on a small dataset that matched the expected conditions of the art installation as closely as possible.
These conditions can be changeable as the experience is positioned differently in every exhibition of the work, but generally we expect dark rooms with lights shining on the faces of participants from a high angle. Also we expect participant’s facial expressions to be more subtle than ‘posed’, or acted-out expressions.
The size of our dataset was smaller than those that were publicly-available, but the quality was high because it was directed towards our needs.
What’s next
This overview has outlined some of the broad topics and concerns of FER system development. My follow-up article explains more about the creation of the EmoPy toolkit, and why and how you might use it in your own projects.
Keep on top of Thoughtworks Arts updates and articles: